概述
在微服务的世界,作为业务运维,总是会遇到几个监控的难题:
1、遇到故障如何快速准确定位到是哪个组件有问题
2、如何准确绘制出业务拓扑图
3、如何快速找到当前的业务瓶颈
以上难题都可以通过分布式追踪解决
作者简介:Paul毕业于中山大学,曾在腾讯做过业务运维,在网易做过游戏开发。 目前是优维平台研发组组长,负责平台的基础架构工作。

背景
分布式链路追踪功能是优维科技EasyOps平台的智能监控模块的一个重要功能。
首先,让我们来看一个EasyOps中自动绘制的业务拓扑图。
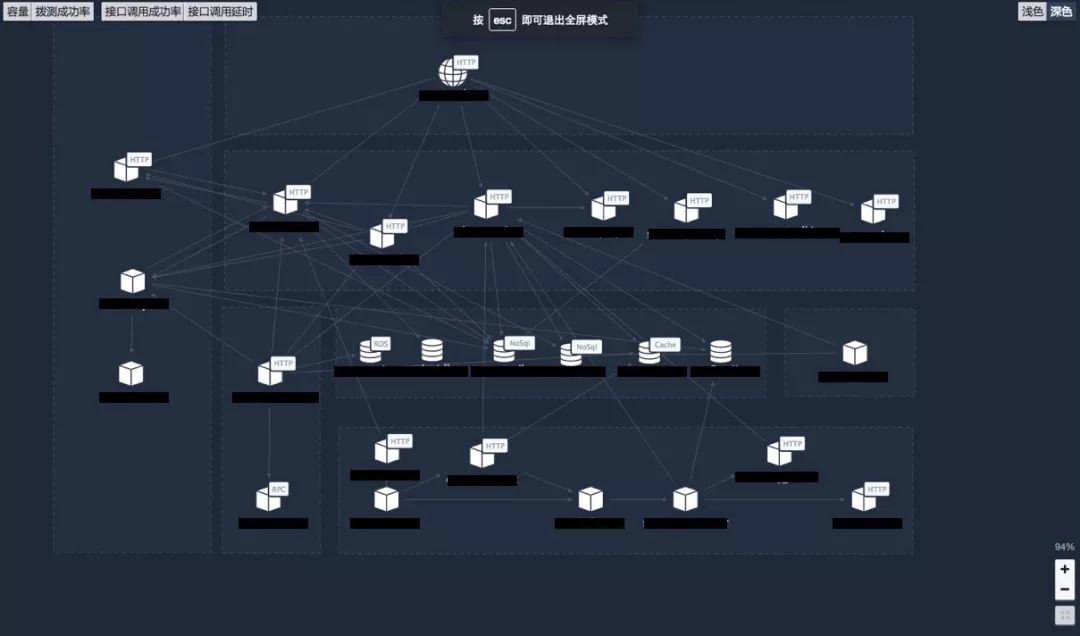
通过分布式追踪,可以很直观地看出来组件与组件之间的关系。
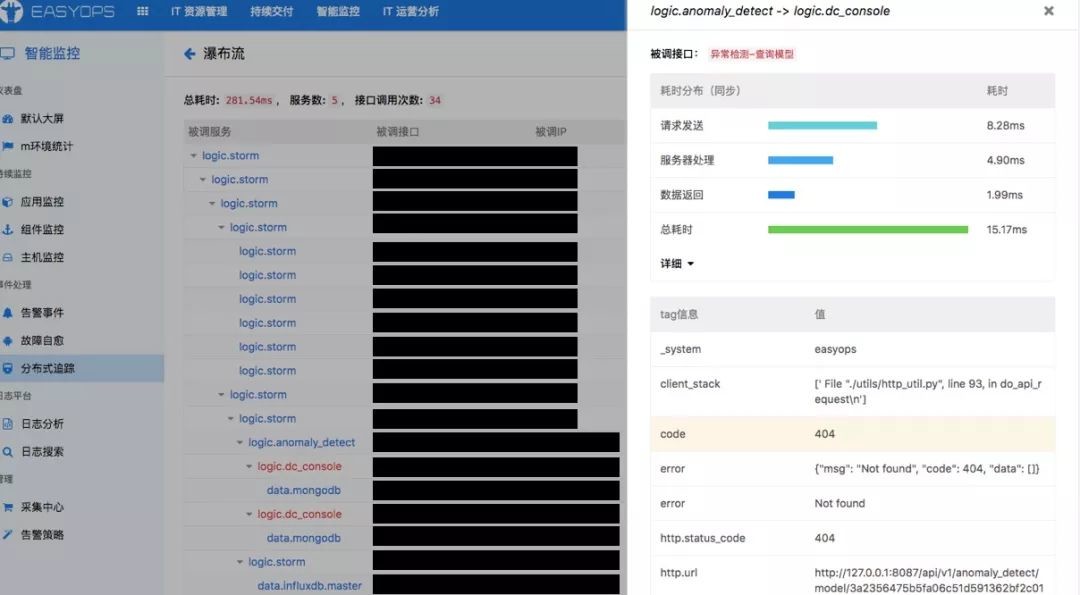
当收到客户投诉时,可以通过分布式追踪定位到错误的服务(下图标红部分)。
技术原理
EasyOps的分布式追踪参考了Google的Dapper论文[1],基于开源项目Zipkin[2]研发了一套分布式追踪的解决方案,目标是通过分布式追踪及时发现生产环境故障以及缩短故障排查时长。
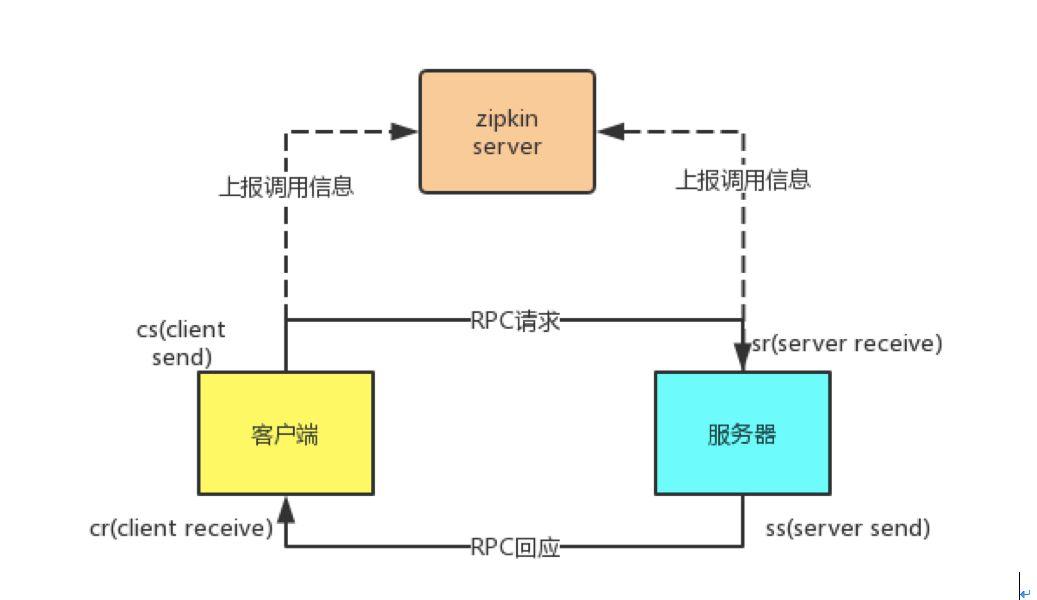
以上是一次常见的RPC调用图,客户端向服务端请求时会给服务器把这次请求的分布式追踪上下文带上(下文称为带内传输)。客户端发送/接收RPC请求和服务器发送/接收RPC请求后,都会给服务器发送一条日志,上报分布式追踪的信息(下文称为带外上报)。通过cs, cr, sr, ss四个时间戳,我们可以算出这一次微服务调用的几个关键时间:
• 请求总耗时:cr – cs
• 服务端逻辑耗时:ss - sr
• 客户端到服务器RTT:sr – cs
• 服务器到客户端RTT:cr - ss
带内传输:
微服务与微服务之间通过唯一的TraceId来传播本次请求的上下文,HTTP常在请求头里面用B3协议来传播上下文。
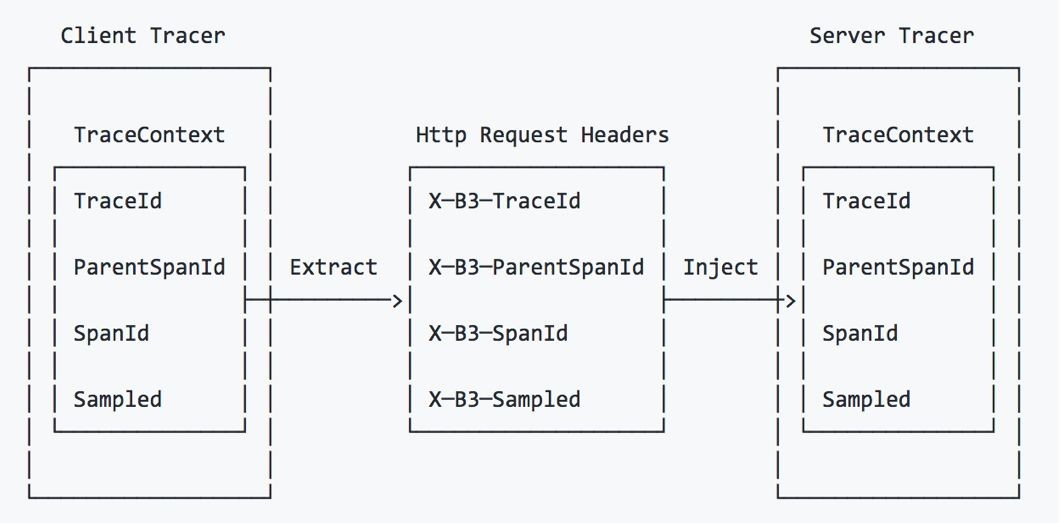
• TraceId: 64位或128位唯一请求ID,随机生成。
• SpanId: 64位RPC唯一ID,每产生一次RPC请求,随机生成一个新的SpanId来追踪。
• ParentSpanId: 当前RPC请求的父节点,用于把整个调度链串起来。
• Sampled: 标记这次请求是否需要采样。请求是否采样由第一个收到请求的Tracer决定。
带外上报:
带外上报会把整个分布式追踪的字段报到服务器(如服务名、IP端口、错误信息等)。上报方式有几种:HTTP, KAFKA, 日志上报。
接入方式:
EasyOps分布式追踪完全兼容Zipkin上报格式[3],提供Java, C#, Go, Python, JavaScript, Ruby, Scala, C,C++等十多种语言的sdk。以下摘取自Zipkin官方文档[4]。
官方支持SDK
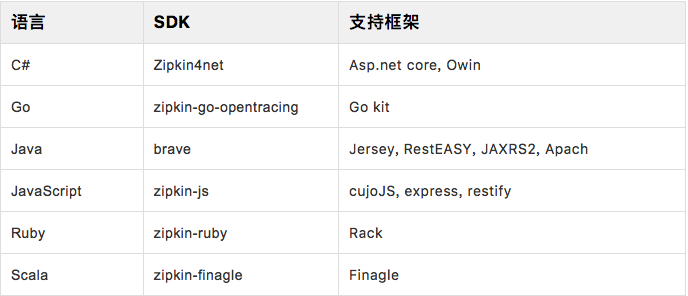
- 开源社区贡献SDK:
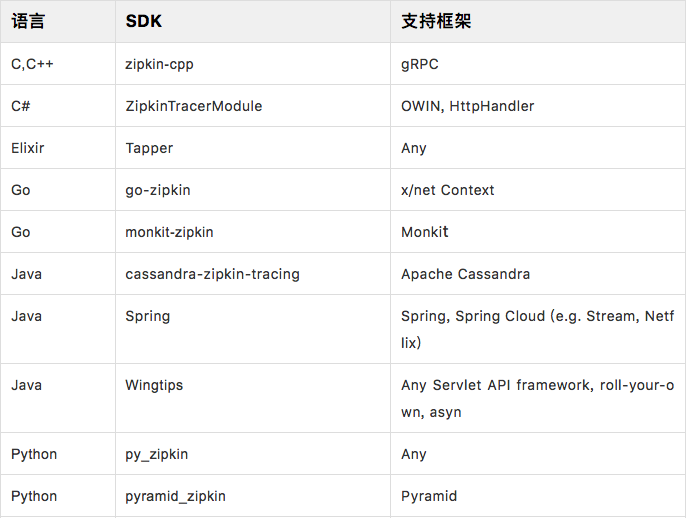
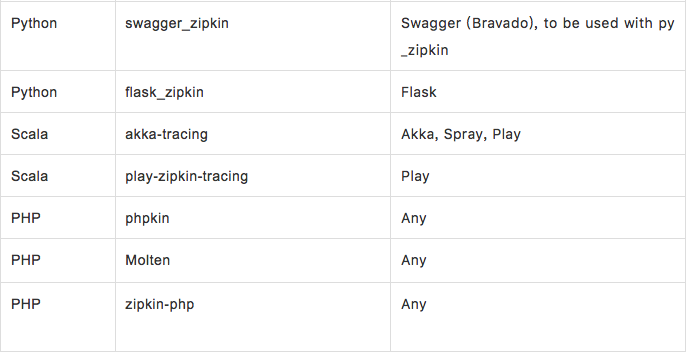
实操演示
三步完成性能分析排查:
第一步: QA发现前台实例搜索很慢,从chrome调试窗口拿到这次请求的TraceId
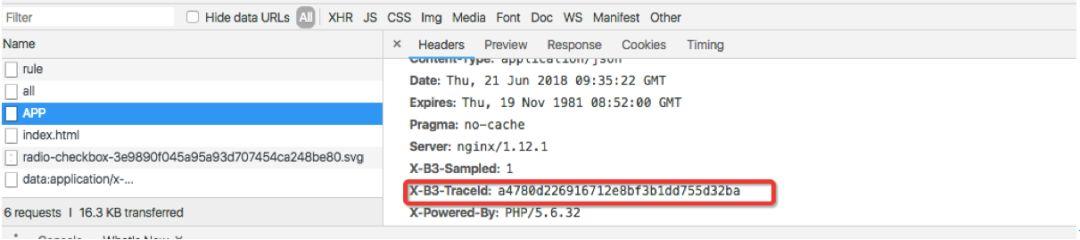
第二步:进入分布式追踪,搜索该分布式追踪的TraceId
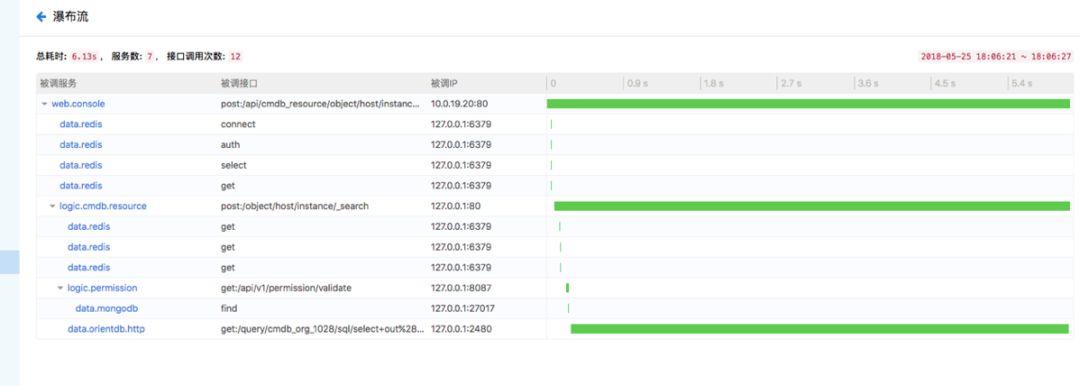
第三步:分析原因,是查询数据库这一步耗时5秒多,定位到是SQL语句写得不合理导致的,提交给开发进行优化。
附录:
[1]Dapper论文:
https://research.google.com/pubs/pub36356.html
[2]Zipkin:
[3]Zipkin上报格式:
https://zipkin.io/pages/data_model.html
[4]Zipkin官方文档: